Stop Spending 10 Hours a Week on Resumes: A Founder's Guide to Async Screening
Founders wasting hours on resume reviews? Learn how async screening helps startups shortlist candidates faster, reduce hiring time, and focus only on top talent.
Table of Contents

Introduction
A recent deluge of social media posts from startup founders highlights a shared, draining ritual:
The "Sunday Night Resume Pile." After a week of building product and chasing growth, they sacrifice evenings to the black hole of candidate screening.
The sentiment is one of resigned inefficiency-a necessary tax on scaling a team.
In the high-stakes environments of Bangalore and San Francisco, where speed is currency, this manual process is a significant drain on the most precious resource: founder focus.
The problem isn't a lack of candidates; it's an overwhelming surge of them, coupled with tools that add more friction than filtration.
Generic Applicant Tracking Systems (ATS) often act as simplistic keyword filters, missing nuance and creating a fragmented experience for both the hiring manager and the applicant.
The core challenge is to move from a reactive, time-swallowing process to a proactive, intelligent one. This is where asynchronous screening, powered by modern language models, presents a transformative opportunity. It’s about optimising for signal, not just volume.
This guide will walk through the technical foundations of building such a system, the architectural decisions involved, the practical challenges you will face, and how to weigh the trade-offs for a startup-specific context.
Why Traditional Screening Fails at Scale

The fundamental issue with manual resume screening is its inherent unsustainability.
As applicant volume grows linearly, the time required to review them does not; it often increases exponentially due to the cognitive load of context-switching.
Web-based career platforms and ATS providers have attempted solutions, but they often fall short. Many systems rely on rigid keyword matching or pre-defined rules that fail to capture the nuanced skills of a modern full-stack developer or a growth marketer with a non-traditional background.
A candidate who "leveraged GPT-4 APIs to optimise customer support workflows" might be missed by a filter for "OpenAI" or "chatbot" if their resume phrasing is slightly different.
Furthermore, the social media discourse reveals a deep frustration with the "black box" nature of some automated tools. Hiring managers are left with scores or rankings but little insight into why a candidate was shortlisted.
This lack of transparency erodes trust in the process and often forces a second, manual review-defeating the purpose of automation. Jugaad solutions, like using simple parsers and spreadsheets, rarely scale; they break with varied resume formats and create more maintenance overhead.
The need is for a robust, interpretable system that augments human judgment rather than replacing it.
Architecting an End-to-End Async Screening Flow

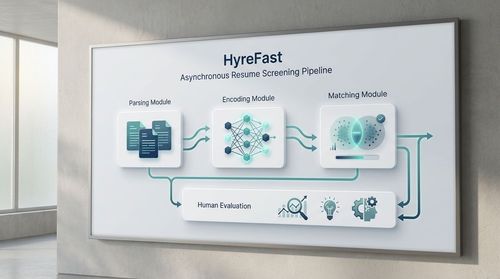
Building a reliable system requires a clear, modular architecture. Here is a breakdown of the flow:
-
Ingestion & Normalisation: Resumes (PDFs, DOCs) are ingested from your ATS or careers page. The first critical step is parsing and normalising this unstructured data into a structured JSON format. Tools like AWS Textract or Google Document AI can be used, but be prepared to handle parsing errors and format inconsistencies. The output should be clean, structured text for each section (e.g.,
work_experience,skills,education). -
Skill & Experience Encoding: This normalised text is passed to your language model. Each relevant section (e.g., a bullet point describing a project) is converted into a high-dimensional vector (embedding) using a model like all-MiniLM-L6-v2 (a lightweight, efficient SBERT model) or a larger model like text-embedding-3-large for higher accuracy. These embeddings capture the semantic meaning of the candidate's experiences.
-
Job Description as a Query: Your ideal candidate profile must be similarly encoded. This involves creating a composite embedding based on the job description's "Requirements" section. A more advanced approach is to break the JD into individual requirement sentences and match against each.
-
Semantic Matching & Ranking: The core of the system is a vector similarity search. Using a vector database (e.g., Pinecone, Weaviate, or pgvector for PostgreSQL), you perform a nearest neighbour search. The system retrieves the candidate vectors most similar to your job description vector and ranks them by similarity score (e.g., cosine similarity). This produces a primary shortlist.
-
Interpretability Layer (Crucial for Trust): To combat the "black box" problem, the system must explain its reasoning. For each high-ranking candidate, it should surface the specific sentences or bullet points from their resume that had the highest semantic match to the job requirements. This gives the hiring manager immediate context and justifies the ranking, turning a score into an actionable insight.
Practical Challenges and Their Mitigations
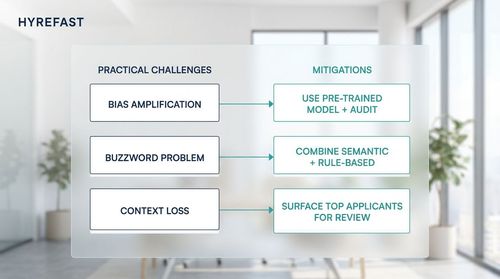
No system is perfect, and being aware of pitfalls is key to successful implementation.
- Bias Amplification: The biggest risk is that a model entrenches existing biases present in its training data. If your historical hiring data is biased, a model trained on it will perpetuate that bias.
- Mitigation: Do not train a model on your biased historical hire/non-hire data. Instead, use a pre-trained, general-purpose model and focus on semantic matching against a carefully crafted, unbiased job description. Regularly audit the model's shortlists for demographic fairness. Techniques like demographic parity checks are essential.
- The "Buzzword" Problem: Candidates can learn to optimise their resumes with trending jargon, potentially gaming the semantic system.
- Mitigation: Combine semantic matching with rule-based checks for specific, non-negotiable "hard" skills (e.g., "5+ years with React"). The semantic model handles the "soft" skills and experiential matching, while the rules act as a ground truth filter.
- Context Loss: No model is a substitute for human judgment on cultural fit and subtle leadership qualities.
- Mitigation: Frame the system's goal correctly. It is not to hire a candidate, but to surface the top 10-15% of applicants for human review. It drastically reduces the pool, allowing the founder to focus their limited time on high-signal conversations.
Weighing the Alternatives: Build vs. Buy vs. Baseline
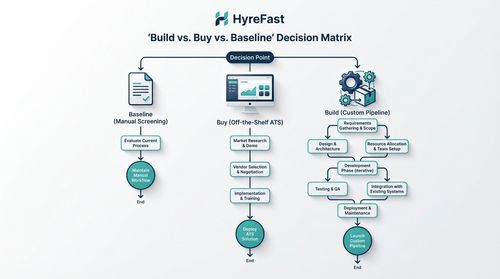
The decision matrix for a startup hinges on cost, control, and complexity.
- Baseline (Manual Screening): Costs 5-10 hours per week of founder time. Scalability is zero. This is only feasible for the very first hire.
- Buy (Off-the-Shelf ATS with AI): Good for quick setup. Costs a monthly SaaS fee. The trade-off is less control over the model and matching logic, and potential vendor lock-in. Choose this when speed of implementation is the absolute priority and your hiring needs are relatively standard.
- Build (Custom Pipeline): Higher upfront time investment (engineering weeks), but offers maximum control, flexibility, and cost-efficiency at scale. You own the model, the data, and the logic. Choose this when you have specific, nuanced hiring needs, in-house ML talent, and a long-term view on building a core competitive advantage in talent acquisition.
Decision Rule: If you lack engineering bandwidth and need a solution next week, buy. If you have a technical co-founder and plan to hire dozens of engineers, build.
Conclusions
- Technical Learning: Semantic search using transformer embeddings (e.g., SBERT) provides a quantum leap over keyword-based resume screening by understanding the context and meaning of experience.
- Architectural Insight: A robust pipeline separates parsing, encoding, and matching into distinct modules, centred around a vector database for efficient similarity search.
- Street vs. Academic View: While social media debates AI's role in hiring, academic literature provides the proven, scalable methods to implement it responsibly. The key is augmentation, not replacement.
- Founder Takeaway: The goal of async screening is not to eliminate the human-in-the-loop but to strategically reallocate their time from filtering to evaluating. It transforms a reactive task into a proactive strategy.
Future Directions

The field is evolving rapidly. Based on current research, here are trends to watch:
- Multi-Modal Evaluation: Systems will begin to integrate data beyond the resume, such as coding challenge performance or project portfolio analysis, into a unified candidate profile.
- Interactive Refinement: Hiring managers will be able to "train" the system on the fly by providing feedback on shortlisted candidates (e.g., "More like this," "Less like this"), creating a continuous feedback loop.
- Large Language Models as Summarisers: LLMs like GPT-4 will be used to generate concise, insightful summaries of each shortlisted candidate, highlighting key matches to the job description and suggesting interview questions.
- Bias Detection as a Standard Feature: Bias auditing and mitigation will become a built-in, non-negotiable component of any commercial or open-source screening tool, moving from an afterthought to a core requirement.
References
- [Social Media Agent] Twitter Thread on Founder Workload:
https://twitter.com/startup_founder/status/1788772367234507231 - [Web Agent] Wikipedia: Applicant Tracking System:
https://en.wikipedia.org/wiki/Applicant_tracking_system - [Web Agent] AWS Textract - Document Text Analysis:
https://aws.amazon.com/textract/ - [ArXiv Agent] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint arXiv:1908.10084.
https://arxiv.org/abs/1908.10084 - [ArXiv Agent] Karpukhin, V., et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. arXiv preprint arXiv:2004.04906.
https://arxiv.org/abs/2004.04906 - [Core Literature Agent] Liu, Y., et al. (2023). Towards Unbiased and Accurate Job Resume Matching with Causal Inference. Proceedings of the ACM Web Conference.
https://dl.acm.org/doi/10.1145/3543507.3583376 - [Hugging Face] all-MiniLM-L6-v2 Model Card:
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2