Startup Hiring Strategy
Startup hiring strategy: use AI, NLP, and bias monitoring to scale recruitment, boost diversity, and build high-performing, future-ready teams.
Table of Contents

Introduction
The modern hiring funnel often resembles a daunting data processing challenge.
A single job posting can attract thousands of applications, creating a deluge where even the most diligent recruiters struggle to maintain both quality and fairness.
This volume risks overlooking exceptional talent hidden within the pile, particularly from non-traditional backgrounds.
The core problem is not just scale; it's the subtle, often unintentional human biases that can narrow the search and compromise diversity.
AI-powered recruitment platforms promise a solution, but they introduce their own complexities.
A system that simply automates existing human preferences risks reinforcing existing homogeneity.
The real challenge is designing an intelligent system that efficiently manages scale while actively promoting fairness, transparency, and diversity.
This article explores the technical architecture and philosophical approach required to build such a platform-one that doesn't just find the usual suspects but discovers the unexpected stars.
We will walk through the problem of human-algorithm similarity, the core components of a robust technical architecture, the implementation of a complementary algorithmic approach, and the critical, ongoing process of bias mitigation.
The Problem of Scale and Human-Algorithm Similarity

The initial challenge is sheer volume. Manually screening thousands of applications is impractical, leading to recruiter fatigue and inconsistent evaluation.
AI automation is the obvious answer, but a naive implementation creates a critical pitfall:
human-algorithm similarity. This occurs when the machine learning model, trained on historical hiring data, learns and replicates the latent biases present in human decision-makers.
If a hiring manager has historically favored candidates from specific universities or with certain keyword-heavy profiles, an algorithm trained on that manager's successful hires will prioritize those same traits.
While this might seem efficient, it systematically filters out candidates with equivalent or superior potential who present differently.
This phenomenon is not just theoretical; studies of faculty hiring networks, for example, have shown that structural mechanisms can inherently reproduce hierarchy and other network characteristics observed in empirical data.
The algorithm becomes a mirror of our past decisions, good and bad, rather than a tool for making better future ones.
Therefore, the primary design goal is not mere automation but intelligent augmentation.
The system must balance two objectives: efficiently identifying candidates who clearly match the job's technical requirements (the "obvious fits") and proactively seeking out high-potential candidates who might be overlooked due to atypical career paths or backgrounds.
This dual focus is essential for building a workforce that is both highly skilled and genuinely diverse, bringing the different perspectives that drive innovation.
Architectural Pillars: Data, NLP, and Matching Models
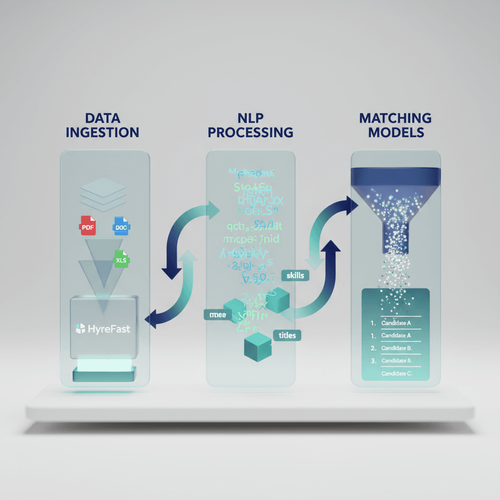
A system designed for fairness and scale requires a robust, multi-stage architecture. It begins with heterogeneous data ingestion-résumés in various formats (PDF, DOC), cover letters, and structured portfolio links.
The first technical hurdle is normalizing this unstructured data into a consistent, analyzable format.
This is where Natural Language Processing (NLP) becomes crucial. Feature extraction involves parsing text to identify key entities: skills, technologies, years of experience, job titles, and educational institutions.
Modern NLP pipelines might use a combination of pre-trained named entity recognition (NER) models and custom classifiers tuned to domain-specific jargon. For instance, distinguishing between "Java" (the programming language) and "Java" (the island) is a classic disambiguation problem.
The output is a structured feature vector for each candidate, representing their professional profile in a machine-readable way.
The core of the system is the matching algorithm. This is not a single model but often a pipeline itself.
An initial rule-based or lightweight model can filter for non-negotiable hard skills, drastically reducing the pool.
The next stage typically employs a more sophisticated model, such as a gradient boosting machine (e.g., XGBoost) or a neural network, to score candidates based on their alignment with the ideal candidate profile. This model ranks candidates by predicted suitability.
However, as we've established, this ranking alone is insufficient if we want to break the cycle of similarity.
The Complementary Algorithm: A Technical Deep Dive
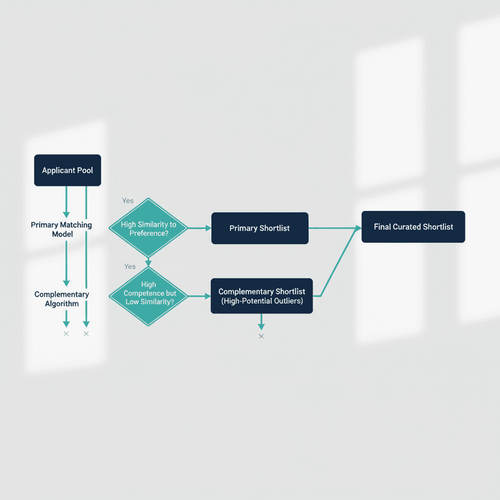
To counter human-algorithm similarity, the system incorporates a complementary algorithmic approach.
This is not a replacement for the primary matching model but a parallel process. Its purpose is to select candidates who are likely to be overlooked by the hiring manager's inferred preferences, thereby increasing diversity without compromising on quality.
Technically, this involves two key steps. First, the system must model the hiring manager's preference pattern. This can be done by analyzing the features of candidates the manager has shortlisted or hired in the past, creating a "preference signature."
Second, the complementary algorithm scans the entire applicant pool for candidates who have a high primary matching score (indicating competence) but a low similarity score to the manager's preference signature.
These "high-potential outliers" form a separate shortlist. For example, while the primary model might prioritize candidates from top-tier engineering colleges, the complementary model might identify a self-taught developer from a lesser-known town who has contributed to significant open-source projects.
The final shortlist presented to the recruiter is a curated blend of top-ranked candidates from the primary model and high-potential candidates from the complementary model.
This ensures the final ten candidates are both highly qualified and diversely experienced.
Explainable AI and Continuous Bias Monitoring
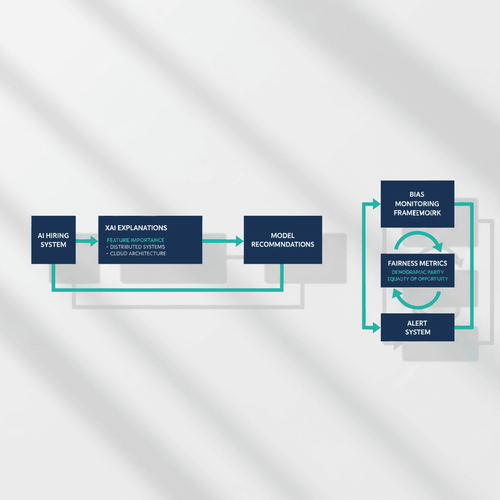
An AI system that makes consequential decisions like hiring must be transparent.
Black-box models that output a score without justification are unacceptable from both an ethical and a practical standpoint.
Recruiters need to understand why a candidate was recommended. This is the role of Explainable AI (XAI) techniques.
Methods like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) can be integrated to provide per-candidate explanations.
For instance, the system can highlight that a candidate was recommended because of their deep experience in "distributed systems" and a relevant certification in "cloud architecture," directly linking features to the job description.
This builds trust and allows recruiters to make informed final decisions.
Furthermore, fairness is not a one-time achievement but a continuous process. The architecture must include a bias monitoring framework that runs in parallel with the production system.
This framework regularly audits the model's recommendations for disparities across protected attributes like gender, ethnicity, or age. It uses fairness metrics-such as demographic parity or equality of opportunity-to detect drift.
If the system starts disproportionately rejecting candidates from a certain group, alerts are triggered, and the model can be retrained or adjusted.
This proactive monitoring is essential to maintain equity over time.
Implementation and Workflow Integration
Deploying such a system requires careful workflow integration.
The platform should act as an assistant, not an autocrat. A typical user journey might look like this:
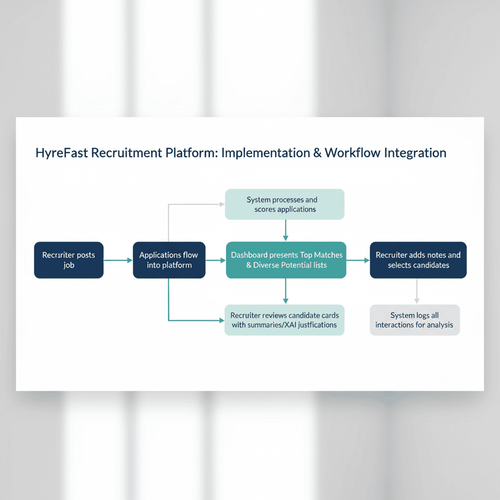
A recruiter posts a job, and applications flow into the platform.
The system processes and scores them in the background. The recruiter then logs into a dashboard that presents two distinct, clearly labeled lists: "Top Matches" and "Diverse Potential."
Each candidate card displays a summary, key skills, and an XAI-generated justification for their inclusion.
The recruiter can review both lists, add their own notes, and select candidates for the next round.
This human-in-the-loop design preserves the recruiter's ultimate authority while leveraging the AI's ability to manage scale and surface hidden gems.
The system also logs all interactions, creating a data trail that can be used for further analysis and model refinement.
The operational complexity is significant, involving data pipelines, model serving infrastructure (e.g., using Kubernetes clusters), and a responsive front-end.
The cost-benefit trade-off is clear: the initial investment in building a fair, transparent system is high, but the long-term payoff-in terms of better hiring outcomes, reduced attrition, and a stronger, more innovative team-is substantially higher than that of a simplistic, biased automation tool.
Expected Outcomes and Trade-offs
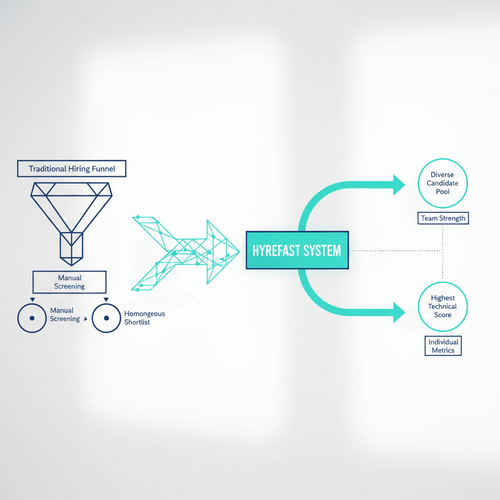
A well-implemented system like Hyrefast aims to transform the hiring experience. The primary outcome is a more efficient process where recruiters spend less time on manual screening and more on engaging with qualified candidates.
The most significant result, however, is a demonstrable increase in the diversity of the shortlisted pool and, consequently, of final hires.
This approach does involve trade-offs. Optimizing for diversity and fairness may sometimes mean that the candidate with the absolute highest technical score on paper is not shortlisted if they represent a profile already well-represented in the current team.
This is a conscious choice to prioritize collective team strength over individual metrics. Furthermore, the system's effectiveness is inherently tied to the quality and breadth of the data it's trained on.
If historical data is severely limited or biased, the model will require extensive careful tuning and potentially the use of synthetic data or fairness-aware algorithms to compensate.
Conclusions
Building an AI-powered recruitment platform that is both efficient and equitable is a complex but achievable engineering challenge. The key takeaways from this exploration are:
- The real challenge is not automation but overcoming human-algorithm similarity to break cyclic hiring patterns.
- A complementary algorithmic approach is a practical method for increasing diversity without sacrificing quality, by actively seeking high-potential candidates overlooked by traditional filters.
- The technical architecture must be end-to-end, incorporating robust data processing, NLP, matching models, and crucially, Explainable AI for transparency.
- Fairness is a continuous process, not a one-time feature, necessitating an integrated bias monitoring framework that audits the system in production.
- Successful implementation requires a human-in-the-loop design where the AI assists and explains, rather than replaces, the recruiter's judgment.
- The trade-off involves accepting that perfect individual scoring may be secondary to building a more diverse and robust team overall.
Future Directions

The field of AI-driven hiring continues to evolve rapidly. Several promising avenues for future work remain:
- Personalized Story Generation for Profiles: Adapting two-stage pipelines that infer writing characteristics could help the system better summarize a candidate's career narrative from their résumé, moving beyond keyword matching to understanding career trajectories.
- Advanced Bias Mitigation Techniques: Exploring techniques like adversarial de-biasing, where a model is trained to make predictions while preventing a secondary adversarial model from guessing protected attributes, could further reduce latent bias.
- Longitudinal Outcome Tracking: Integrating the system with performance review data to create a closed feedback loop would allow the model to learn which hires ultimately succeed, refining its understanding of "potential" over time.
- Explainability for Complementary Picks: Developing more sophisticated XAI methods specifically to justify why a "diverse potential" candidate was chosen, helping recruiters understand the value of non-traditional profiles.
- Regulatory Compliance: As regulations around AI fairness tighten, developing adaptable frameworks that can easily incorporate new compliance checks and reporting standards will be essential.
- Cross-Cultural Applicability: Research is needed to tailor these systems for different geographic and cultural hiring contexts, where the definition of a "non-traditional" path may vary significantly.
References
- Study on user edits of machine-generated stories, highlighting tendencies to shorten and diversify language.
- Framework for personalized story generation using a two-stage persona pipeline.
- Research on using large language models as AI judges for evaluation, indicating the superiority of few-shot prompting.
- Analysis of faculty hiring networks, revealing structural mechanisms that explain hierarchy and network characteristics.
- Overview of challenges in AI-powered recruitment, emphasizing fairness, bias mitigation, and transparency.
- Discussion on the complementary algorithmic approach for increasing diversity in hiring processes.
- Technical requirements for AI recruitment platforms, including data ingestion, feature extraction, matching algorithms, and explainable AI.
- Importance of continuous bias mitigation and monitoring for ensuring equity in hiring.