The Psychology of Interviewing: What Resumes Will Never Tell You
Explore the psychology of interviewing and how AI-driven analysis uncovers traits resumes miss, helping reduce bias and improve smarter hiring decisions.
Table of Contents

Introduction
The Psychology of Interviewing: What Resumes Will Never Tell You For any founder or hiring manager, the resume is the starting pistol of the hiring race. It lists skills, universities, and job titles-the hard, quantifiable facts.
But we all know, instinctively, that a CV is a deeply incomplete portrait. It tells you what a person has done, but remains silent on the qualities that truly determine success in a fast-paced environment: resilience, collaborative spirit, ethical reasoning, and the subtle patterns of problem-solving. This silence is a significant business risk.
The traditional interview, our tool for bridging this gap, is notoriously unreliable, often falling prey to our own cognitive biases. However, an emerging field, powered by advances in artificial intelligence, is offering a new, more objective lens. T
his article explores how computational psychology, specifically using Large Language Models (LLMs), is beginning to uncover what resumes will never tell you, transforming hiring from an art into a more disciplined science.
We will dissect the fundamental flaws in our current approach, explore a cutting-edge methodological blueprint from recent research, and outline a practical technical architecture for implementation.
For startups and technical leads, the focus will be on actionable insights, cost-benefit trade-offs, and ethical considerations, moving beyond theory to practical application.
The High Cost of Superficial Assessment

A resume is a curated highlight reel. It confirms a candidate has experience in a certain programming language or has managed teams of a certain size.
But the critical nuances are absent. Did they lead that team through inclusive collaboration or top-down coercion? Did they solve that complex scalability issue through innovative architecture or simply by working heroic, unsustainable hours? These behavioural fingerprints are invisible on paper.
The interview process, intended to probe these depths, is itself a variable and flawed instrument. Psychological research, consistent with general HR wisdom, highlights several pitfalls.
Confirmation bias leads us to ask questions that subconsciously confirm our first impression, formed perhaps in the first thirty seconds of the meeting.
The halo effect can cause one strong skill, like eloquent communication, to overshadow gaps in technical depth. Furthermore, the very structure of human judgment is inconsistent. Intriguingly, research into AI systems, such as the study "Exploring the psychology of LLMs' Moral and Legal Reasoning" (Almeida et al., 2023), indirectly underscores this human flaw.
If sophisticated models can exhibit unpredictable and context-dependent reasoning, it highlights the profound variability of the human interviewer's subjective evaluation.
The cost of this inconsistency is tangible, especially for startups. A bad hire is not just a financial drain on salary; it's a cost measured in lost momentum, team morale, and missed opportunities.
The need is clear: we require methods that can provide a deeper, more objective psychological profile, moving beyond the curated CV and the biased interview.
A Research Blueprint: From Clinical Assessment to Hiring Insight
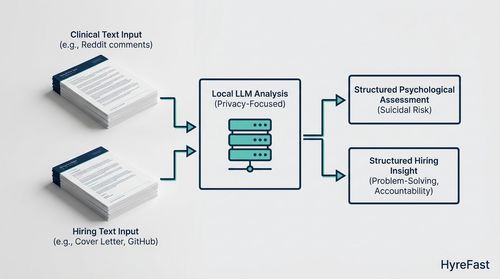
The most direct application of this idea comes from unexpected academic quarters. Sergi Blanco-Cuaresma's 2024 paper, "Psychological Assessments with Large Language Models:
A Privacy-Focused and Cost-Effective Approach," provides a compelling methodological blueprint.
While the study's focus was on assessing suicidal risk from Reddit comments, its core innovation is highly transferable to the hiring context.
The research's power lies in its use of LLMs not as conversational chatbots, but as sophisticated, evidence-based text analysis engines. The team utilised open-source models like LLaMA, specifically prioritising those with lower computational demands.
This focus on efficiency is crucial for practical implementation, ensuring cost-effectiveness and enhancing privacy, as sensitive data need not leave a local server. The key to their success was a meticulously crafted prompt and a "grammar" that constrained the LLM's output. This guidance forced the model to perform a specific task: pinpoint exact excerpts from a user's text that supported a predefined psychological assessment.
Translated to hiring, this is the leap from a generic "tell me about a challenge you faced" to a structured, auditable analysis. The instruction becomes:
"From this candidate's collection of texts-their cover letter, GitHub READMEs, and technical blog posts-identify concrete evidence for traits like 'systematic problem-solving,' 'accountability in failure,' and 'constructive communication.'"
The LLM acts as a tireless, unbiased analyst, sifting through textual evidence to build a supported psychological profile.
Architecting a Practical Assessment System

Building on this research, we can outline a potential system architecture for a psychologically-aware hiring tool. This pipeline moves far beyond simple keyword matching to a semantic understanding of behavioural traits.
- Data Curation (The Input Layer): The system's input is a portfolio of a candidate's textual outputs, creating a richer dataset than a lone resume. This portfolio could include:
- The cover letter and personal statement.
- Technical writings: blog posts, project documentation, or detailed README files.
- Answers to thoughtfully designed, open-ended application questions.
- (With explicit consent) A written response to a simulated work task or a case study.
- The Analysis Engine (The Core Logic): At the heart of the system is an open-source LLM, such as a fine-tuned version of LLaMA 2 or Mistral. The model's effectiveness is dictated almost entirely by the prompt design, which acts as the AI's interview script. Following Blanco-Cuaresma's evidence-based approach, a prompt might be structured as follows:
"Analyse the provided candidate text portfolio. For each of the following traits-Resilience, Integrity, and Curiosity-perform the following:
- Identify up to three direct excerpts that serve as evidence FOR the candidate possessing this trait.
- Identify up to three excerpts that serve as evidence AGAINST it.
- For each excerpt, provide a one-sentence justification linking the text to the trait."
- Insight Generation (The Output Report): The output is not a simplistic score but a qualitative, evidence-based report. It highlights specific phrases and provides reasoned analysis. For example: "Evidence for Accountability: The candidate wrote, 'The project failed because I underestimated the complexity of the third-party API integration.' Justification: This shows first-person ownership of a setback rather than attributing blame externally."
This transforms the hiring dialogue from a gut-feeling statement ("I liked them") to a data-informed observation ("Their written communication demonstrates a pattern of owning mistakes, which is supported by these specific examples").
Navigating the Implementation Trade-Offs

For a pragmatic leader, the appeal of a deeper assessment is clear, but the implementation hurdles are the real test. Here are the key trade-offs and mitigating strategies.
- Privacy and Ethical Guardrails: This is the paramount consideration. The open-source, on-premise approach outlined in the research is a strong foundation for privacy. However, technology is no substitute for ethics. Transparent consent is non-negotiable. Candidates must be clearly informed about what data is being analysed and how the results will be used. The system must be carefully designed to avoid inferring protected characteristics (e.g., race, gender, health) and must never become a black-box tool that automatically disqualifies candidates. Its purpose is illumination, not automated judgement.
- Cost vs. Performance Optimization: The research deliberately favoured smaller, more efficient models. The trade-off is nuanced understanding. A 7-billion-parameter model can run cost-effectively on a single GPU, making it accessible for a startup. However, its analysis may lack the subtlety of a state-of-the-art model like GPT-4. The decision rule is straightforward: begin with a smaller, private model. If the insights generated are too superficial for your needs, then-and only then-consider using a larger, API-based model for critical roles, ensuring strict data anonymisation protocols are in place.
- Augmenting, Not Replacing, Human Judgement: This technology's greatest value is as a complement to human intuition. It is a tool for flagging areas requiring deeper exploration. If the LLM's report notes a lack of detail in problem-solving explanations, a human interviewer can prepare specific, behavioural questions to probe that area during the live interview. This symbiotic relationship is underscored by other AI research, such as "InCharacter:
Evaluating Personality Fidelity in Role-Playing Agents" (Wang et al., 2023). Their work on assessing AI personality through dialogue reminds us that true depth of character is often revealed in dynamic, interactive exchange, not just static text analysis. The LLM prepares the interviewer; the interviewer validates and explores the findings in real-time.
Future Directions: The Evolving Landscape of Hiring

The integration of these technologies points toward a future where hiring is more data-informed and less prone to human bias. The trajectory suggests several key developments:
- Multi-Modal Analysis: Future systems will likely integrate text analysis with video interview processing, assessing paralanguage and tonal patterns to create a more holistic profile.
- Longitudinal Fit Analysis: Instead of a one-off assessment, AI could analyse a team's communication patterns (e.g., via Slack or email, with privacy safeguards) to identify the behavioural traits of top performers, creating a dynamic "culture fit" model.
- Standardisation and Benchmarking: As these methods mature, we may see the emergence of standardised, validated benchmarks for assessing specific behavioural traits, moving beyond proprietary, black-box personality tests.
Conclusion
The resume is a necessary document, but it is a relic of a time when hiring was more about credentials than cohesion.
The psychology of interviewing is what separates good teams from great ones. By embracing research-driven approaches from computational psychology, we can move beyond the limitations of both the CV and the biased interview.
The method outlined here-using evidence-based LLM analysis of a candidate's own words-provides a structured, auditable, and deeply insightful way to understand the person behind the qualifications.
For organisations serious about building resilient, high-performing cultures, the tools to see what resumes hide are now within reach.
The future of hiring lies not in discarding human judgment, but in empowering it with unprecedented clarity.
References
- Almeida, T., et al. (2023). Exploring the psychology of LLMs' Moral and Legal Reasoning. ArXiv. (Illustrates the variability in structured reasoning, analogous to human interview bias).
- Blanco-Cuaresma, S. (2024). Psychological Assessments with Large Language Models: A Privacy-Focused and Cost-Effective Approach. ArXiv. (Primary source for the evidence-based LLM methodology and architecture).
- Wang, Z., et al. (2023). InCharacter: Evaluating Personality Fidelity in Role-Playing Agents. ArXiv. (Highlights the importance of interactive exchange for assessing character depth).
- Harvard Business Review & Forbes general articles on behavioural interviewing and cognitive bias. (Provided foundational context for the problems with traditional interviews).