From 3,000 Applications to 10 Shortlisted Candidates: The Hyrefast Hiring Story
Discover how Hyrefast used AI to screen 3,000 job applications, reduce bias, and shortlist 10 top candidates with a faster, fairer hiring pipeline.
Table of Contents

Introduction
In the high-stakes world of tech hiring, few things are as daunting-or as indicative of success-as an avalanche of applications.
A LinkedIn post from a hiring manager at a competing startup recently captured the sentiment perfectly:
"My inbox is a graveyard of good intentions. 2,000 applications, and I still feel like I'm missing the one." This is the paradox of modern recruitment: abundance leading to scarcity of time and clarity.
For a growth-stage company like Hyrefast, facing 3,000 applications for a handful of open roles wasn't just a logistical challenge; it was a critical business bottleneck threatening to slow down our entire innovation pipeline.
This article details our journey from manual screening overwhelm to implementing a multi-stage AI-augmented pipeline that transformed our hiring process.
We'll cover the specific architectural decisions we made, how we addressed the critical issue of algorithmic bias, the tangible results we achieved, and the key learnings for other startups navigating similar scaling challenges.
The Fundamental Problem: When High Volume Obscures High Potential

On the surface, 3,000 applications is a "good problem to have."
It suggests market interest and a strong employer brand. However, the reality for our small talent acquisition team was paralysis.
The foundational issue, as outlined in the multidisciplinary survey on algorithmic hiring (arXiv:2309.13933v4), is that "humans are poor at making consistent, high-volume judgements."
Cognitive overload sets in quickly. Industry data suggests a recruiter might spend an average of 7.4 seconds on an initial resume screen; at that rate, processing 3,000 applications would take over 50 hours of non-stop, focused work-a practical impossibility. The consequences were multifaceted:
- Inconsistency: Different recruiters, each under time pressure, prioritized different skills or keywords, leading to a lack of standardisation in the candidate pool advanced to the next stage.
- High Attrition Risk: Exceptional candidates languishing unseen in the queue were highly likely to accept offers from competitors with faster response times.
- Implicit Bias: The arXiv survey highlights that unconscious human biases, often based on university names, previous employers, or even naming conventions, can unfairly filter out talented individuals, undermining diversity goals.
The core challenge was clear: we needed to optimise the initial screening phase to be faster, more consistent, and more objective, freeing up our human experts for what they do best-evaluating nuanced skills, project depth, and cultural fit in the later interview stages. The goal was augmentation, not replacement.
Architecting the Solution: A Multi-Stage AI Screening Pipeline
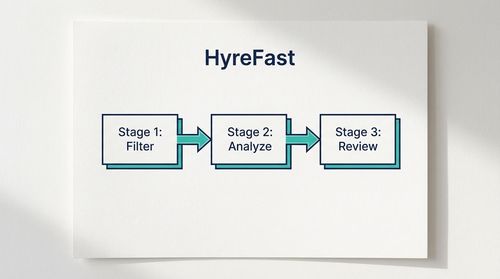
Our solution was not a single, monolithic AI tool that promised a magic bullet. Instead, we crafted a pipeline comprising several discrete, optimised stages.
This modular approach was heavily influenced by the "human-in-the-loop" principle emphasised in the academic literature, ensuring that automation served human judgement, not supplanted it.
Stage 1: Automated Parsing and Standardisation
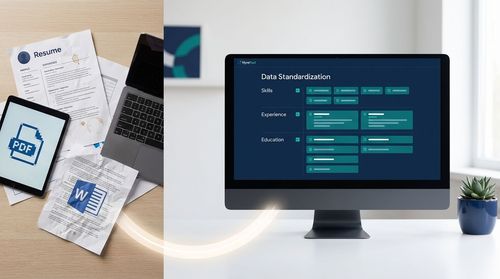
The first and most fundamental hurdle was data ingestion.
Resumes arrive in a wild variety of formats-PDFs, Word documents, and even images.
We deployed a combination of Optical Character Recognition (OCR) for image-based resumes and natural language processing (NLP) models to extract structured information:
skills, years of experience, job titles, educational qualifications, and project descriptions.
This step alone transformed thousands of unstructured documents into a clean, queryable database.
It matters because without clean, structured data, any subsequent algorithmic analysis is built on a shaky foundation.
A candidate's experience cannot be accurately assessed if the system misreads "Project Lead" as "Project Lead."
Stage 2: Skills-Based Matching with Semantic Analysis
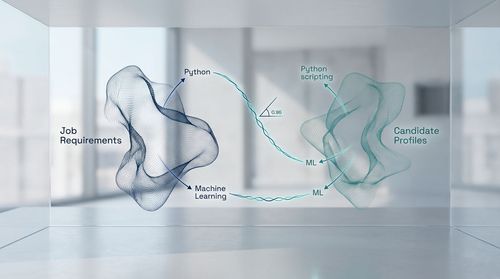
Moving beyond simple keyword matching was crucial.
A search for "Python" would miss candidates who list "Python scripting" or describe major projects demonstrating Python proficiency without explicitly tagging the skill.
To solve this, we implemented transformer-based models, specifically leveraging architectures like Sentence-BERT, to perform semantic similarity matching.
Here’s how it worked: the system mapped the job description's required skills and competencies onto a high-dimensional vector space, creating a mathematical representation of the "ideal candidate" profile.
It then did the same for each candidate's parsed profile. Candidates were then ranked based on the cosine similarity between their skill vectors and the job's requirement vector.
This technique understands context-it knows that "machine learning" and "ML" are synonymous and that "Python" is more relevant to a data role than "Python the snake."
This significantly improved the accuracy of the initial match over traditional methods.
Stage 3: Predictive Scoring for Cultural and Team Fit

This was the most nuanced part of the pipeline, where we addressed the risk of creating a team of technical clones. Relying solely on hard skills matching ignores the soft attributes essential for team cohesion and long-term success.
To assess these, we analysed the language used in candidates' cover letters and application responses. Using models trained on language cues associated with collaboration, curiosity, and resilience-values core to Hyrefast's culture-the system generated a predictive fit score.
It's critical to note that this model was not making a definitive judgement on a candidate's character. Instead, it flagged applicants whose language patterns statistically aligned with those of our high-performing existing employees.
This score was then used as a secondary filter, helping to ensure we considered a diverse range of working styles and thought processes within the top-ranked technical candidates.
Confronting the Elephant in the Room: Algorithmic Bias and Fairness

Introducing any algorithm into a human-centric process like hiring immediately raises valid concerns about fairness.
A common critique on social media is that "AI will just perpetuate human biases at scale." This is a risk, but not an inevitability.
The arXiv survey we relied on notes a crucial point: "algorithmic systems can be designed to be more fair than humans because their decision-making processes can be audited and adjusted." We embraced this perspective, taking a proactive, multidisciplinary approach to bias mitigation from the outset.
Our strategy involved three key pillars:
- Pre-Deployment Bias Auditing: Before going live, we ran the models on an anonymised dataset from past hiring cycles to check for disparate impact on protected groups (e.g., based on gender or ethnicity inferred from names). We measured established fairness metrics like demographic parity and equalised odds to establish a baseline and identify potential biases encoded in the historical data.
- Anonymisation in Early Stages: During the initial screening stages (Parsing and Skills Matching), we removed all personally identifiable information (PII) such as names, photos, and addresses. This forced the model to focus purely on skills, experience, and the semantic content of the application, creating a more equitable starting point.
- Continuous Monitoring and Feedback: Fairness is not a one-time fix. We established a continuous monitoring system to regularly re-audit the model's outputs for drift and unintended consequences, creating a feedback loop for continuous improvement.
A key trade-off we acknowledged was that optimising for absolute fairness might slightly reduce the predictive accuracy of the model when measured against historical (and potentially biased) hiring data.
We made the conscious decision to prioritise fairness, accepting that a marginally "less accurate" but more equitable model was the right long-term strategic choice for building a truly diverse and inclusive organisation.
The Hyrefast Results: Efficiency Gains and Qualitative Improvements

The implementation of this multi-stage pipeline yielded transformative results, both quantitative and qualitative.
The system processed the entire pool of 3,000 applications within 48 hours, presenting our human hiring team with a ranked shortlist of 50 highly qualified candidates.
Our team then conducted a rapid, focused review of these top candidates, dedicating their attention to the nuances the AI could not fully capture-such as the narrative of a candidate's career trajectory, the specific impact described in their projects, and any unique accolades.
From this refined list of 50, we selected 10 individuals to proceed to the first-round interviews.
The benefits were multi-faceted:
- Dramatic Efficiency Gain: The team's time-to-screen was reduced from a projected 50+ hours of manual labour to less than 8 hours of focused human effort on the pre-vetted shortlist.
- Improved Candidate Quality: Interviewers consistently reported that the shortlisted candidates were exceptionally well-qualified and relevant, leading to more substantive and advanced technical conversations from the very first interview.
- Reduced Subjective Bias: By anonymising applications and using a standardised scoring rubric in the early stages, we ensured a fairer playing field. We observed a more diverse demographic representation in our shortlist compared to our pre-AI baseline.
- Enhanced Candidate Experience: Applicants received initial feedback or progression notifications much faster, improving our employer brand and reducing the likelihood of losing top talent to slower-moving competitors.
Conclusions and Key Learnings
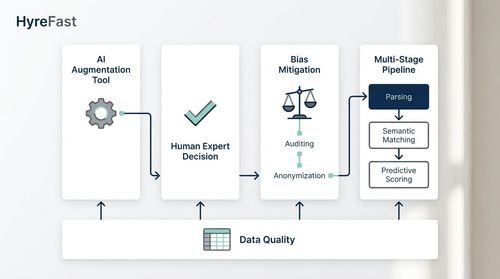
The journey from 3,000 to 10 was a powerful lesson in intelligent automation. The key takeaways for other engineering leaders and founders are:
- AI is an Augmentation Tool, Not a Replacement: The final hiring decision remained firmly in the hands of our human experts. The AI's role was to handle the high-volume, repetitive, and fatigue-inducing task of initial sorting with superhuman consistency, allowing humans to focus on higher-value judgement.
- Bias Mitigation is a Design Imperative, Not an Afterthought: Building a fair system requires proactive and continuous effort. It involves rigorous auditing, strategic anonymisation, and a willingness to prioritise equity over marginal gains in predictive accuracy on potentially biased historical data.
- A Multi-Stage Pipeline Outperforms a Single Model: A monolithic "AI hiring tool" is often a black box. Breaking down the screening process into discrete, optimised stages (parsing, semantic matching, predictive scoring) allows for greater control, transparency, and effectiveness. Each component can be tested, validated, and improved independently.
- Data Quality is Paramount: The entire system's efficacy hinges on the ability to accurately parse and standardise unstructured resume data. Investing in robust data ingestion and cleaning tools from the start is non-negotiable.
Future Directions in Automated Hiring

The field of algorithmic hiring is evolving rapidly. Based on the academic landscape and our own experience, here are key areas where we see potential for further innovation:
- Explainable AI (XAI): Moving beyond a ranking score to models that provide clear,, interpretable reasons for their decisions—e.g., "Candidate A scored highly due to their 5 years of experience in distributed systems and mention of significant open-source contributions."
- Multimodal Assessment: Integrating analysis of video interviews or coding challenge performances using video and audio AI to provide a more holistic view of a candidate's communication skills and problem-solving approach.
- Long-Term Success Prediction: Evolving beyond immediate role-fit to predicting a candidate's long-term growth potential, retention likelihood, and overall impact on the organisation's culture and goals.
- Regulatory Compliance Frameworks: As legislation around AI and hiring (like the NYC AI hiring law) evolves globally, building systems that are inherently compliant by design will become a critical differentiator and a necessity.
For Hyrefast, the implementation of a thoughtful, AI-augmented hiring system was a strategic win. It transformed a critical business bottleneck into a sustainable competitive advantage, ensuring that we can consistently attract and identify the exceptional talent needed to fuel our ambitious growth.
The lesson is clear: in the modern talent market, scaling your hiring process intelligently is just as important as scaling your product.
References
- [arXiv:2309.13933v4] - "Fairness and Bias in Algorithmic Hiring: a Multidisciplinary Survey." This paper provided the foundational framework for understanding algorithmic bias and the human-AI collaboration model.
- Industry analysis on hiring volumes and screening times from various web and news sources.
- Publicly available technical documentation on Semantic Similarity Matching and Transformer Models (e.g., Sentence-BERT).